 【自适应】Zeexo主题88套样
【自适应】Zeexo主题88套样 【城市分站系统源码】带
【城市分站系统源码】带 【自适应】响应式跨境外
【自适应】响应式跨境外 【自适应】响应式通信电
【自适应】响应式通信电个人站长做网站大多喜欢采集,因为人力物力有限,没办法像门户站那样自己创造资源,大批量的转载文章也比较累,采集文章成了一个省时省力的办法,轻轻松松获得百万文章数据。火车头采集器是一款十分优秀的国产采集工具,免费版也十分强大,而火车头采集器破解版之类,这里不做评价,大家还应尊重版权,毕竟免费版已经很强了。
常规文章采集简单,而采集瀑布流、点击加载、下拉加载这种类ajax式的列表页面就比较困难了,让很多新手无从下手,CMS大学特别整理本篇文章,教大家在使用帝国cms采用火车头采集器进行采集时,如何采集这些页面。
首先目标页面需要抓包,简单站的抓json数据即可,如果壳网等;难一些的站需要post方式,还需要填cookie、随机值,如蘑菇街等。
今天咱们先来个简单的,以采果壳网为例进行说明。
首先需要使用的是chrome浏览器(调试帝国cms模板时也推荐使用chrome浏览器)。
一、首先在目标页面按F12或Ctrl+Shift+C打开审查元素,然后点Network选项卡。
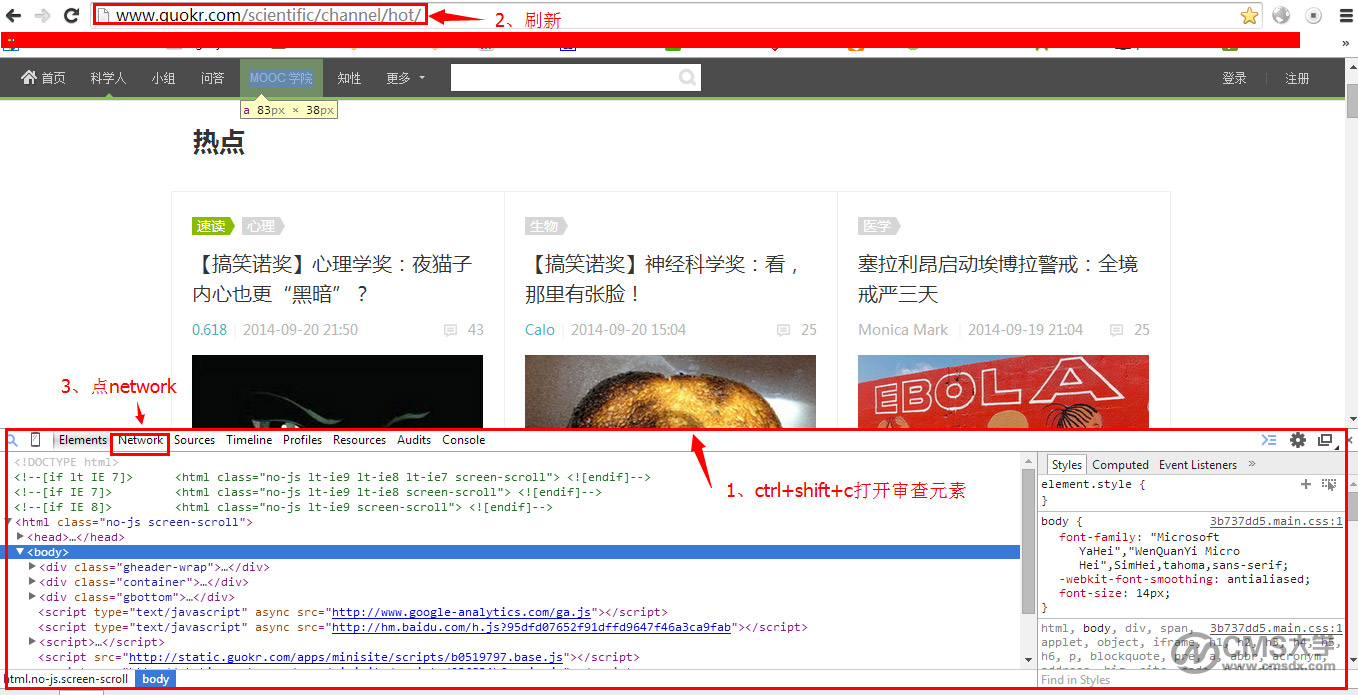
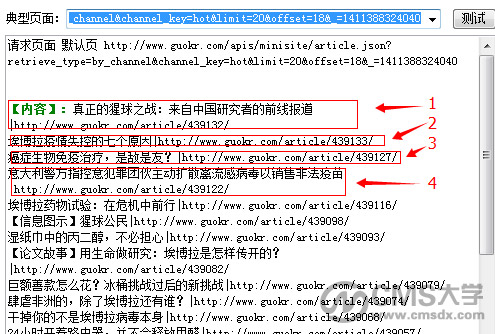
二、点击XHR按钮,在页面上触发ajax加载,浏览器即监测到页面的数据执行和变化,红框中即为抓取到的数据地址。
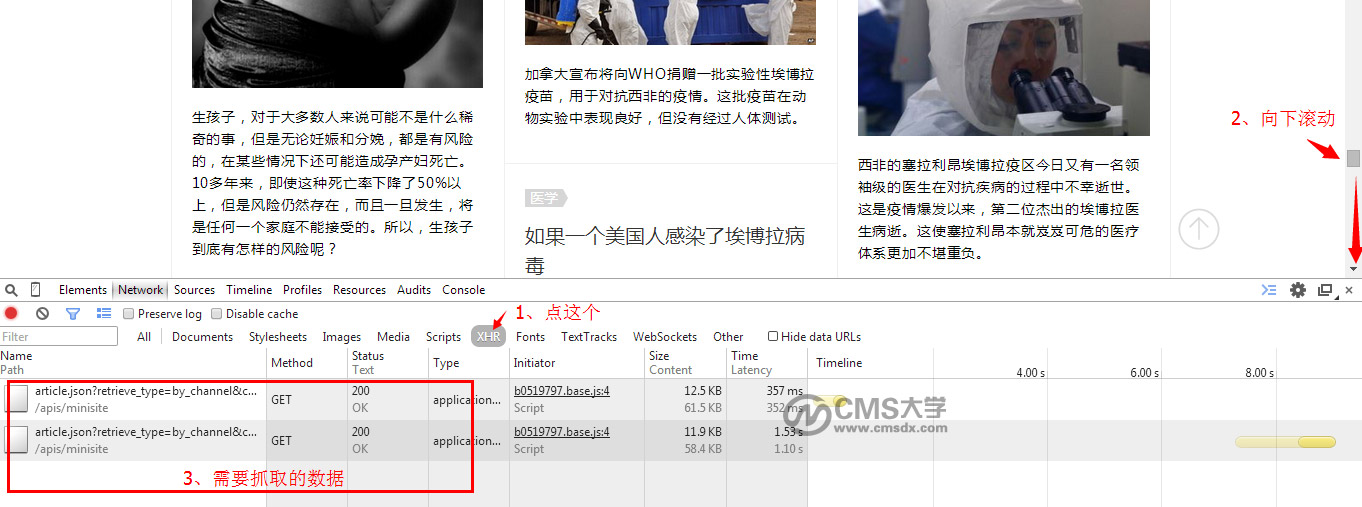
三、点击数据地址,右侧出现详细信息,注意观察请求地址url的规律,例如下图中,有时间戳和页面序号。


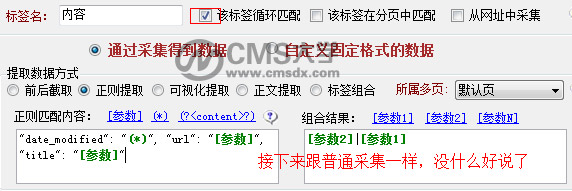
四、在火车头采集器中添加如下抓取到的地址,并设置好地址规则,然后便是常规的火车头设置了。
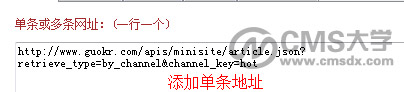
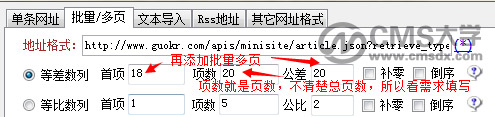
至此,这个让很多帝国cms小白望而却步的ajax页面采集就做完了,大家还有什么好点子,也欢迎一起交流。