 【带手机】建筑工程地产
【带手机】建筑工程地产 【自适应】国际物流海运
【自适应】国际物流海运 蓝色机械设备pbootcms网站模
蓝色机械设备pbootcms网站模 【自适应双语】红色科技
【自适应双语】红色科技1、添加超级采集
登录您网站后台,模块->采集侠->超级采集,点击添加任务2、设置规则
【采集入口地址】采集入口地址就是采集侠自带采集爬虫从哪个页面开始爬取页面,可以是采集对象的任意一个页面地址,我们一般选择链接多的页面,以便可以保证可以顺利抓取到对方网站的全部页面,比如首页地址
我们以中国站长站为例,采集入口地址我们就直接填写:http://www.chinaz.com/
【绑定栏目id】
意思就是采集之后保存到哪个栏目,这个一定要设置正确的栏目id的,否则采集之后的文章保存到系统里你也将看不到,
查看栏目ID的方法,织梦自己的程序的 核心菜单->常用操作->网站栏目管理->每个栏目名称后面写着的ID数字,要采集到哪个栏目就把他的ID填写到超级采集的【绑定栏目ID】里
【标题规则】
标题规则就是告诉采集侠对方网站哪段文字是标题,想想,一个页面里有很多文字,但是哪句话是标题呢?采集侠具有一定的思考能力,可能大部分它都能猜出标题是什么,但也有出错的时候,所以如果你要确保它一定是准确的,就需要自己去告诉他
那么如何告诉它,我们继续以中国站长站为例,找到对方网站中一篇最常规的文章地址,如:http://www.chinaz.com/news/2015/1203/478430.shtml,打开后,右键查看源码,在原源码找到这篇文章的标题《诺基亚股东批准176亿美元收购阿朗2016年Q1完成交易》的位置,如图所示:

最后我们把上面的代码串起来就成了标题规则
<title>[内容] - 站长之家</title>
注:中间的 [内容] 这里是固定格式,意思就是这个位置就是我要的内容了
【作者规则 / 来源规则】
这是采集对方网站的文章的作者和来源的,这对大部分网站来说都不是特别必要,我们建议留空即可,或者到采集侠的高级设置去设置固定的作者和来源
【内容规则】
内容规则是最重要的,是告诉采集侠怎么去识别一个网址里的文章内容,设置方法和标题规则是一样的,例如这篇文章的内容,还是以中国站长站刚才那篇文章为例

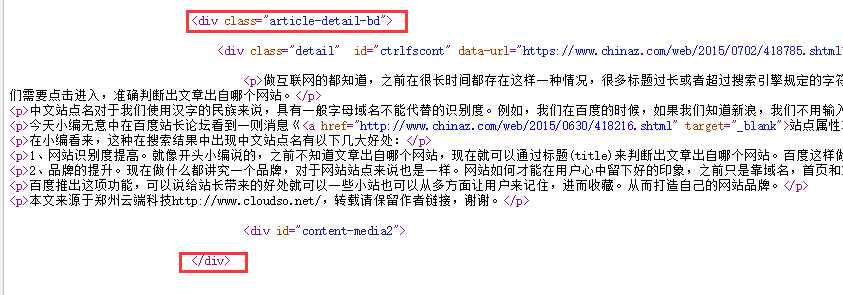
内容规则就是
<div class="article-detail-bd">[内容]</div>
超级采集的规律和定向采集是很类似的,如果还没有看懂,可以再看看定向采集的说明,理解了原理之后就很容易了